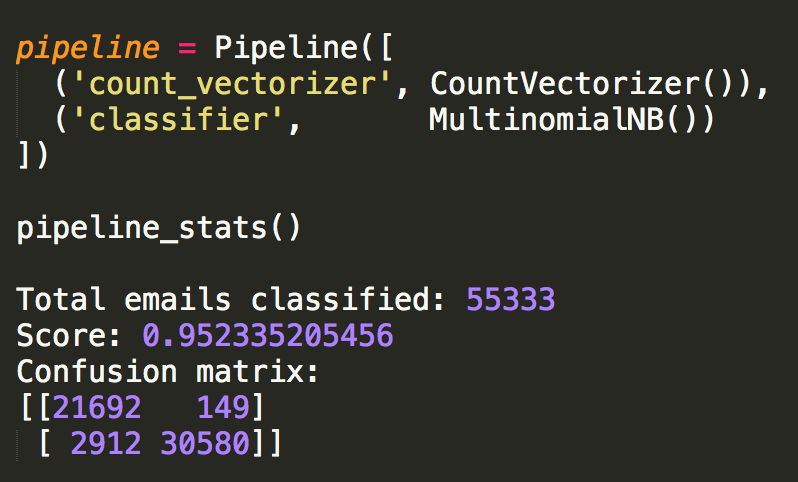
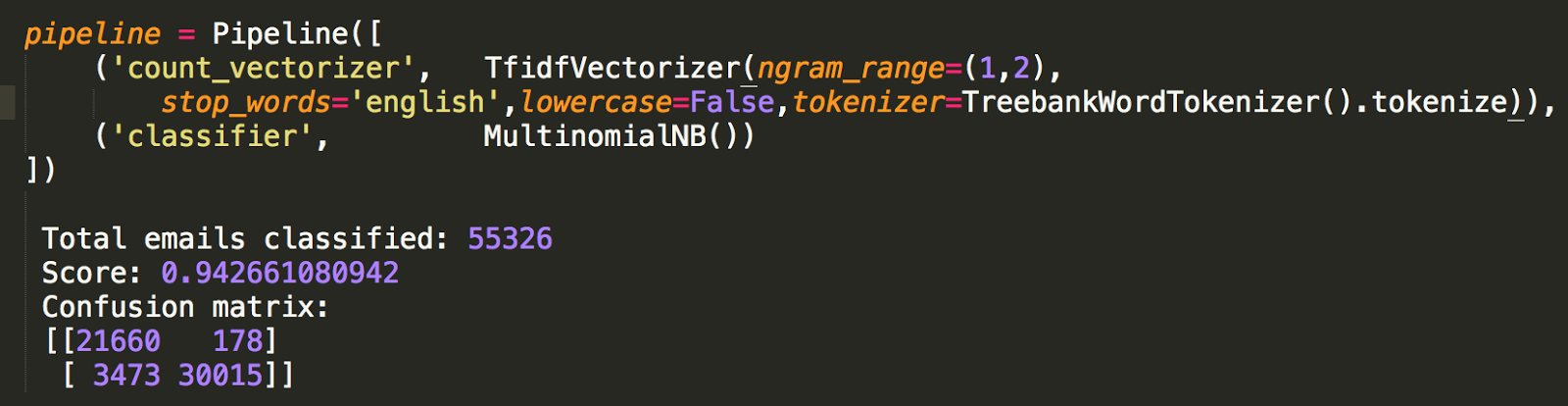
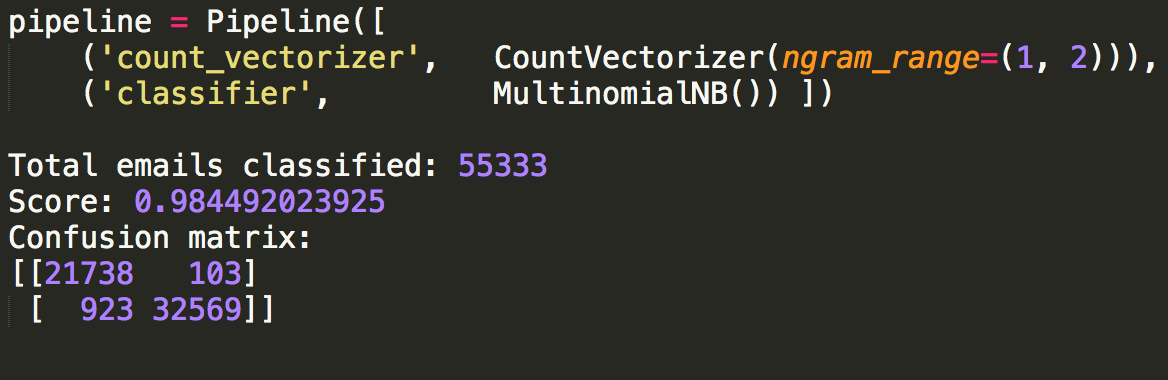
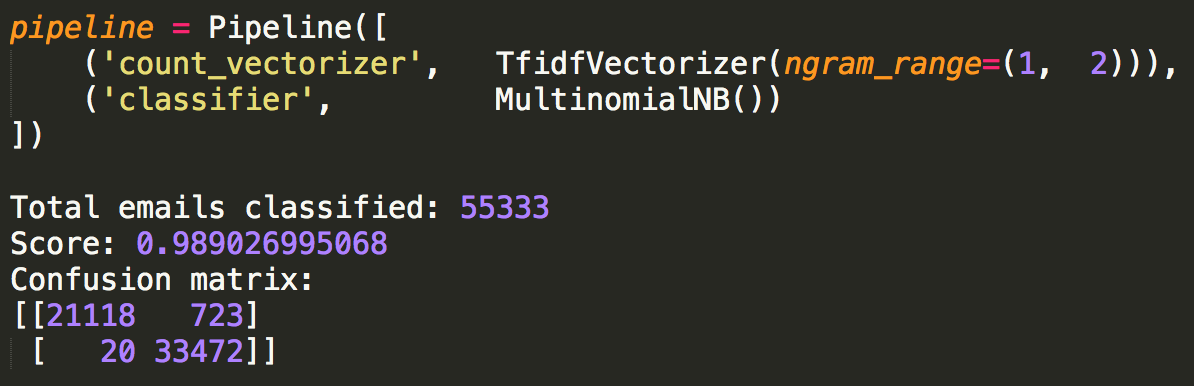
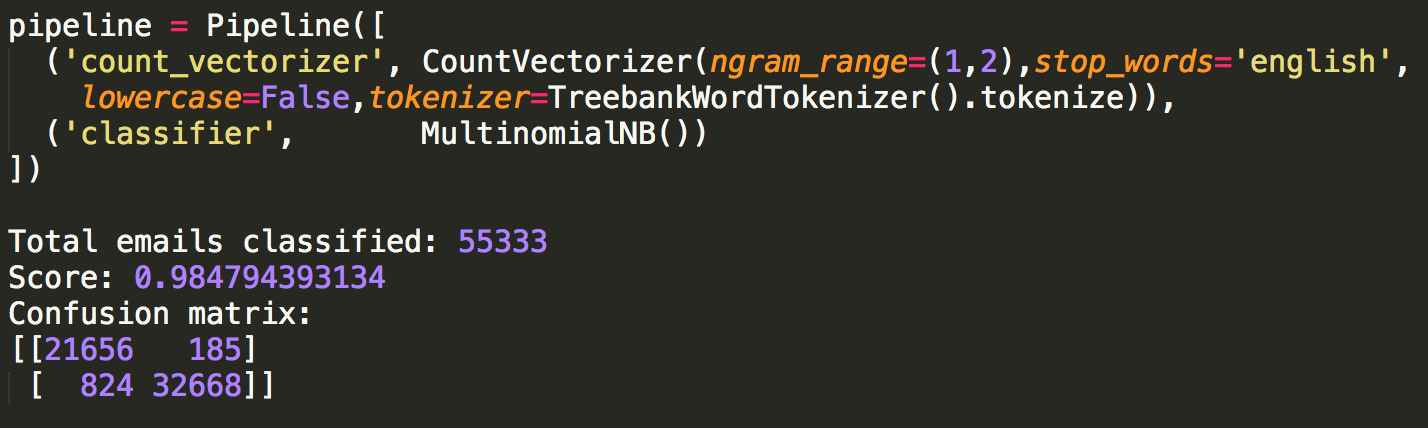
One of my favorite homework assignments in database class was to find the "Kevin Bacon number" of given actors. I ended up downloading data from IMDB to help me with the assignment and my implementation is below.
###PostGRES
#SELECT actor_id, name, 999 AS kb INTO kb_number FROM actors;
#SELECT 4986
#Python3
import psycopg2
conn = psycopg2.connect("dbname=movies-duffrind user=duffrind")
cur = conn.cursor()
#I chose levenshtein instead of metaphore so that no matter how badly the name is misspelled, it will always return something.
def find_kb():
kb_num()
actor_name = input('Input actor name: ')
cur.execute(
"""SELECT name, kb FROM kb_number
WHERE levenshtein(lower(name), lower(%s)) =
(SELECT min(levenshtein(lower(name),lower(%s))) FROM kb_number);""",
(actor_name, actor_name))
output = cur.fetchall()
for i in output:
print('Actor: ',i[0],'\nKevin Bacon Number: ',i[1])
def kb_num(act = 2720, actor_list = [2720], movie_list = [], depth = 0):
new_actors = []
new_movies = []
cur.execute(
"""SELECT kb FROM kb_number WHERE actor_id = %s;""",
(act,))
num = cur.fetchall()
if depth < num[0][0]:
cur.execute(
"""UPDATE kb_number SET kb = %s WHERE actor_id = %s;""",
(depth, act))
cur.execute(
"""SELECT movie_id FROM movies_actors WHERE actor_id = %s;""", (act,))
movies = cur.fetchall()
for movie in movies:
if (movie[0] not in movie_list) and (movie[0] not in new_movies):
movie_list.append(movie[0])
new_movies.append(movie[0])
for movie in new_movies:
cur.execute(
"""SELECT actor_id FROM movies_actors WHERE movie_id = %s;""", (movie,))
actors = cur.fetchall()
for actor in actors:
if (actor[0] not in actor_list) and (actor[0] not in new_actors):
new_actors.append(actor[0])
actor_list.append(actor[0])
for actor in new_actors:
kb_num(actor, actor_list, movie_list, depth + 1)
find_kb()
Output:
Input actor name: 50 sant
Actor: 50 Cent
Kevin Bacon Number: 103
Input actor name: kevan bekan
Actor: Sean Bean
Kevin Bacon Number: 7
Input actor name: kevin bakon
Actor: Kevin Bacon
Kevin Bacon Number: 0